

在数字化转型的浪潮中,数据已成为政府和企业最宝贵的资产之一。然而,随着数据量的爆炸性增长和数据来源的多样化,如何有效管理和利用这些数据成为企业面临的重要挑战。数据血缘作为数据治理的重要组成部分,正逐渐成为政府和企业构建数据生态的基石。
一、什么是数据血缘?
数据血缘是在数据的加工、流转过程产生的数据与数据之间的关系。提供一种探查数据关系的手段,用于跟踪数据流经路径。数据血缘通常包括以下关键信息:
1.数据来源:数据最初是从哪里产生的,比如数据库、文件、外部系统或手动输入等。
2.处理过程:数据在流转过程中经历了哪些处理步骤,包括转换、清洗、聚合等操作。
3.流转路径:数据在系统内部或系统之间流转的路径,涉及的各个系统、表、字段和程序。
4.数据去向:数据最终被用于何处,比如报告、分析模型、业务决策支持等。
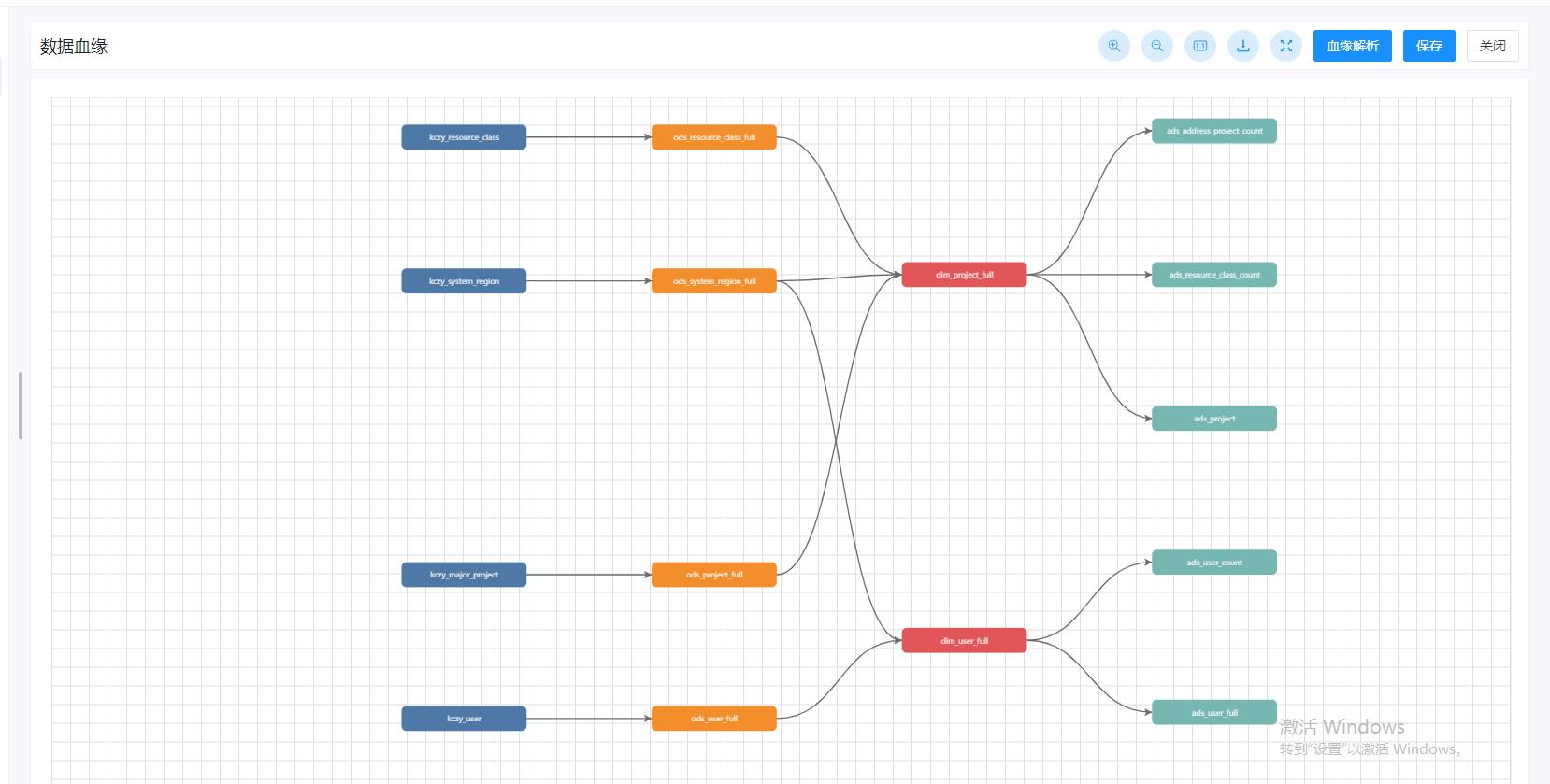
二、数据血缘的组成
1.数据节点
数据血缘中的节点,可以理解为数据流转中的一个个实体,用于承载数据功能业务。例如数据库、数据表、数据字段都是数据节点。
按照血缘关系划分节点,主要有以下三类:流出节点->中间节点->流入节点
流出节点: 数据提供方,血缘关系的源端节点。
中间节点: 血缘关系中类型最多的节点,既承接流入数据,又对外流出数据。
流入节点: 血缘关系的终端节点,一般为应用层,例如可视化报表、仪表板或业务系统。
2.节点属性
当前节点的属性信息,例如表名,所属数据库,所属数据源等。

3.流转路径
数据流转路径通过表现数据流动方向、数据更新量级、数据更新频率三个维度的信息,标明了数据的流入流出信息:
数据流动方向: 通过箭头的方式表明数据流动方向
数据更新量级: 数据更新的量级越大,血缘线条越粗,说明数据的重要性越高。
数据更新频率: 数据更新的频率越高,血缘线条越短,变化越频繁,重要性越高。
三、数据血缘价值和应用场景
1.流程定位,追踪溯源
通过可视化方式,将目标表的上下游依赖进行展示,一目了然。
2.确定影响范围
通过当前节点的下游节点数量以及类型可以确定其影响范围,可避免出现上游表的修改导致下游表的报错。
3.评估数据价值、推动数据质量
通过对所有表节点的下游节点进行汇总,排序,作为数据评估依据,可重点关注输出数量较多的数据节点,并添加数据质量监控。
4.提供数据下架依据
例如以下数据节点,无任何下游输出节点,且并无任何存档需求,则可以考虑将其下架删除。
5.归因分析,快速恢复
当某个任务出现问题时,通过查看血缘上游的节点,排查出造成问题的根因是什么。同时根据当前任务节点的下游节点进行任务的快速恢复。
6.梳理调度依赖
可以将血缘节点与调度节点绑定,通过血缘依赖进行ETL调度。
7.数据安全审计
数据本身具有权限与安全等级,下游数据的安全等级不应该低于上游的安全等级,否则会有权限泄露风险。
可以基于血缘,通过扫描高安全等级节点的下游,查看下游节点是否与上游节点权限保持一致,来排除权限泄露、数据泄露等安全合规风险。
四、数据血缘如何建设
1.定义元数据模型:首先需要确定需要管理的元数据类型,如数据库表、字段、ETL过程、数据仓库模型等,并定义元数据的属性,包括名称、描述、数据类型、来源、去向等。
2.收集元数据:从各种数据源(如数据库、数据仓库、ETL工具、数据湖等)中提取元数据,利用元数据抽取工具或服务自动化地收集元数据。
3.建立血缘关系模型:确定血缘关系的类型,如上游/下游关系、父子关系、依赖关系等,设计血缘关系图模型,以图形化的方式表示元数据之间的关系。
4.追踪数据流动:通过对数据清洗、数据流向等任务的分析,提取数据流动和流向的血缘数据,同时支持自动和手动方式,最终实现应用程序血缘的数据采集。
5.可视化分析:将收集到的元数据和血缘关系以可视化的方式展示,便于理解和分析。
6.持续更新和维护:对数据血缘进行持续的更新和维护,确保数据的最新状态被准确记录。
7.应用分析结果:将分析结果应用于实际的数据管理和优化中,如新旧表切换、字段口径探查、指标自动化拆解等。
智政数智平台,提供了完整的数据血缘功能,支持从数据调度任务以及元数据等不同的角度去查看数据血缘关系,满足不同场景的需求。通过数据血缘图谱,可以对数据的流转流向关系进行清晰的查看。从而为数据治理、数据清洗等提供全面的数据关系服务。
关注智政科技

全国客户服务热线:400-615-2018
智政科技 版权所有 www.zzdsj.com.cn 苏ICP备19007259号-1  苏公网安备 32011202000232号
苏公网安备 32011202000232号
"AI+"数据与智能应用服务提供商
